PDF Slurping
I’ve been using Advantage Archives for looking at the newspaper archives of a number of different libraries as a part of genealogy research.
The trouble is that each library has a slightly different UI for browsing these newspapers, and the experience can be fairly cumbersome. Ultimately, you can download a PDF if you want, but all the clicking around still makes the process slow and frustrating.
Of course the built-in MacOS Preview tool can show you PDFs, too, and it’s navigation/zoom interface is easier, too (especially using pinch-to-zoom, etc).
Could automation make this a bit more friendly? I bet it can! And I’ll throw in a little “vibe coding” on top of it.
When navigating to a result link for the “Correctionville Argus” at the Archives of the Correctionville Public Library (an Advantage Archives-powered site), I can take a look at the URL in my browser: https://correctionville.advantage-preservation.com/viewer/?k=reyman&i=f&d=01011906-12311910&m=between&ord=k1&fn=correctionville_news_usa_iowa_correctionville_19101020_english_8&df=1&dt=10&cid=2823
If I open my browser’s developer tools, I can see there’s a request made to
“GetPdfFile”, or https://correctionville.advantage-preservation.com/viewer/GetPdfFile?85357268.
Hmm, it seems like I could directly download the PDF if I know that number (85357268).
So from the command line I curl the original page URL
curl "https://correctionville.advantage-preservation.com/viewer/?k=reyman&i=f&d=01011906-12311910&m=between&ord=k1&fn=correctionville_news_usa_iowa_correctionville_19101020_english_8&df=1&dt=10&cid=2823" | pbcopy
This pipes the HTML contents of the page onto my clipboard. From here I paste it into a text editor and search for the magic number 85357268.
Aha!
<input id="hdnFilename" name="FileName" type="hidden" value="correctionville_news_usa_iowa_correctionville_19101020_english_8" /><input id="hdnSearchKey" name="Search" type="hidden" value="" /><input id="hdnCollectionId" name="CollectionId" type="hidden" value="2823" /><input id="hdnBacktoSERPLink" name="BacktoSERPLink" type="hidden" value="" /><input id="hdnPubDateId" name="PublicationDateID" type="hidden" value="85357268" />
Now, I’m an experienced coder and I could code all of this up manually, but thought I’d try a bit of “vibe coding”.
Here I’m going to link to my full ChatGPT chat so you can see how I iterated on it, but I’ll hit the highlights here:
I want a shell or python script that takes a URL as an input argument, fetches it, then extracts a value from the HTML. within the page, what I want to extract is contained within this type of structure:
(then I pasted the html excerpt from above)
And in this example the value is the 85357268. You don’t need to do really fancy html parsing, it might be possible to obtain this value with a simple grep or similar. Then I want it to fetch a PDF using that value. In this example the full URL is https://correctionville.advantage-preservation.com/viewer/GetPdfFile?85357268 So the base URL + the extracted value. That file should be stored locally on disk, then the file should be opened using Mac OS’s open command.
And it spit out a script that did that!
Then I said
great! add a variable at the top for the destination directory and make the filename the extracted value.pdf
and it did that too!
But then I noticed one thing I was missing that the site shows – the publication date, which I need for the citation! I got to looking a bit closer at that HTML, and then told ChatGPT:
Also the date of the publication in the PDF is hidden in that input string:
value="correctionville_news_usa_iowa_correctionville_19101020_english_8"Here the date value is19101020. So YYYYMMDD. Can you extract that, and then use it to name the output PDF as YYYY-MM-DD.pdf ?
It output a new script version, and now the date is in the filename and that filename is easily visible when it is auto-opened in Preview by the script.
Oh shoot, I need the page number, too, which the site shows! Not every archived image actually shows the page number because they didn’t always print them. I got to looking a bit closer at that HTML, and then told ChatGPT:
I also want you to extract the page number. In this example it is “8”, from after the “english” <input id=“hdnFilename” name=“FileName” type=“hidden” value=“correctionville_news_usa_iowa_correctionville_19101020_english_8” Use the page number when naming the file: YYYY-MM-DD-page-8
And oh, it’d be nice to have the date in the format I want, just so I don’t have to do the mental swap-a-roo on the month and day.
Instead for the filename use the format 20 October 1910 page n.pdf
The script is done and I didn’t code any of it! It would’ve taken me a lot longer to code it up myself.
Now to put it all together. I made a Keyboard Maestro shortcut to call the script with the contents of my clipboard:
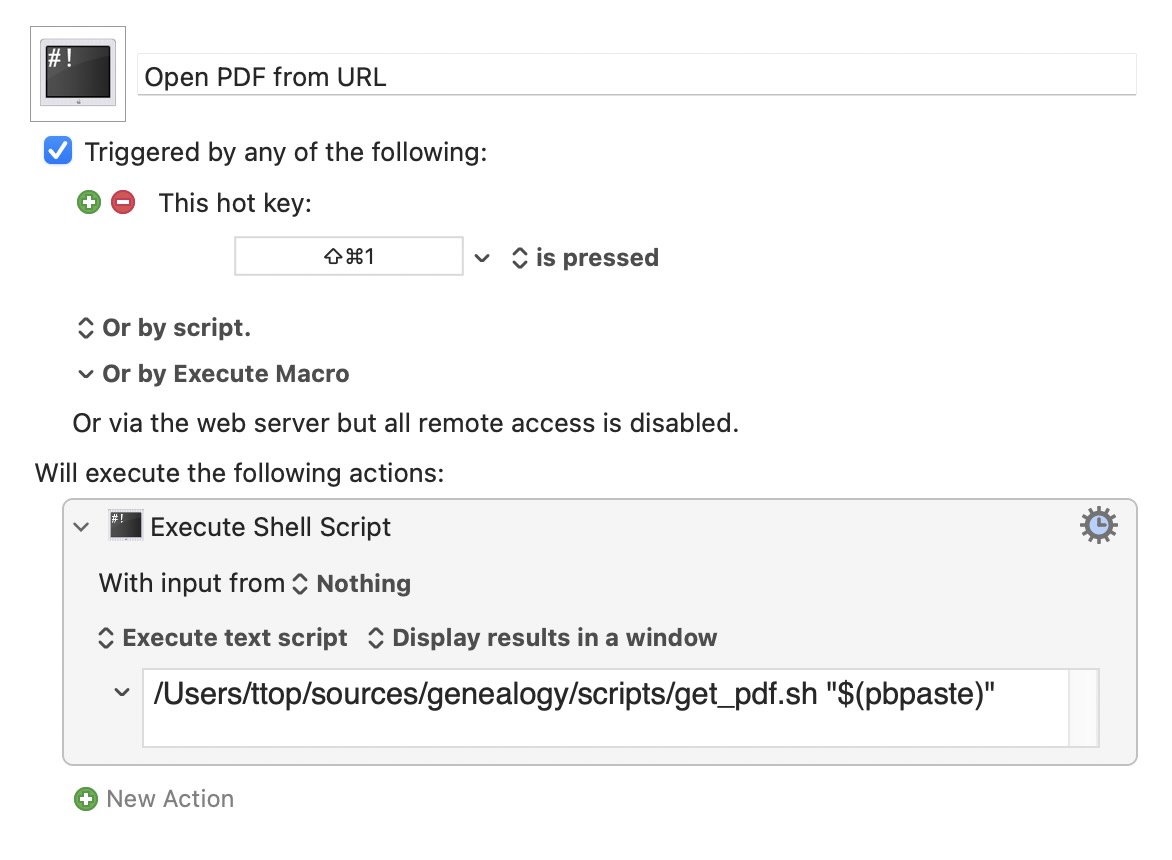
So now, I don’t even have to open the paper from the website. From the search results list, I can context-click and “Copy Link” – now it’s on my clipboard and I press ⇧⌘1. The script immediately executes and a moment later the PDF opens in the Preview app.